

Understanding Encoder-Decoder Mechanisms and the Evolution of Transformer Models in Artificial Intelligence (P1)
Abstract
In this comprehensive guide (covered in two articles), we explore the intricate world of encoder-decoder mechanisms and their transformative impact on artificial intelligence (AI). These mechanisms lie at the core of many AI applications, particularly in Natural Language Processing (NLP), enabling complex tasks such as machine translation, text summarisation, and information retrieval. We delve into the mathematical foundations that underpin these mechanisms, covering vectors, matrices, and functions, as well as discussing the significance of tokens and tokenization.
Moreover (in the second article), we thoroughly examine the game-changing evolution of Transformer models and the introduction of self-attention mechanisms. Throughout this journey, we highlight notable examples of Transformer models like BERT, GPT, and BARD. From their beginnings in recurrent neural networks (RNNs) to the present-day Transformer models, we analyse the challenges and limitations encoder-decoder mechanisms face. Finally, we glimpse into the future of AI and the potential innovations that will shape the next generation of encoder-decoder models.
Table of Contents (Article 1):
- Introduction
1.1 Encoder-Decoder Mechanisms in AI
1.2 Applications of Encoder-Decoder Mechanisms in NLP
- The Role of Encoders and Decoders
2.1 Understanding Encoders and Embeddings
2.2 Decoders and the Generation of New Data
- The Significance of Tokens and Tokenization
3.1 Defining Tokens in NLP
3.2 Tokenization Techniques and Examples
- The Mathematical Backbone: Vectors, Matrices, and Functions
4.1 Introduction to Vectors in AI
4.2 Working with Matrices in Encoder-Decoder Models
4.3 Mathematical Functions and Their Role in Encoder-Decoder Models
4.3.1 The Softmax Function
4.3.2 The Attention Mechanism
")

Introduction. The Role of Encoders and Decoders
Section 1: Introduction
1.1 Encoder-Decoder Mechanisms in AI
Artificial Intelligence (AI) has made significant advancements in various fields, and at the core of many AI applications, particularly in Natural Language Processing (NLP), lie encoder-decoder mechanisms. These mechanisms are fundamental in transforming one sequence of data into another, making them invaluable for tasks such as machine translation, text summarization, and information retrieval.
Encoder-decoder models work in tandem, with the encoder responsible for converting the input sequence into a condensed and meaningful representation called an “embedding.” On the other hand, the decoder utilizes the embeddings provided by the encoder to generate a new sequence. This symbiotic relationship allows seq2seq models to handle tasks involving varying input and output sequence lengths, making them versatile tools in the field of AI.
1.2 Applications of Encoder-Decoder Mechanisms in NLP
The significance of encoder-decoder mechanisms becomes evident in their applications across various areas of NLP. One such application is machine translation, where the encoder processes the source language sequence, and the decoder generates the corresponding translated sequence in the target language.
Additionally, encoder-decoder models find use in text summarization tasks, where the encoder abstracts the input text, and the decoder generates a concise summary of the content. Information retrieval is another area where these mechanisms play a pivotal role, enabling the extraction and conversion of relevant information into a more accessible format.
These applications showcase the versatility and power of encoder-decoder models in tackling complex NLP challenges.
Section 2: The Role of Encoders and Decoders
2.1 Understanding Encoders and Embeddings
Encoders serve as the first component of encoder-decoder mechanisms, and their role is critical in transforming raw input data into a more manageable format for processing. In the context of NLP, an encoder takes a sequence of input data, such as words in a sentence, and converts it into a continuous representation known as an “embedding.”
An embedding is a compact and dense vector representation that captures the essential elements and relationships of the input sequence. The process of generating embeddings involves learning representations that preserve the semantic and contextual information present in the input data. These embeddings are essential for downstream tasks, enabling the decoder to generate meaningful and coherent output sequences.
The concept of embeddings is pervasive in NLP, and various embedding techniques, such as word embeddings (e.g., Word2Vec and GloVe) and sentence embeddings (e.g., Doc2Vec and Universal Sentence Encoder), are widely used to transform text data into continuous vector representations.
2.2 Decoders and the Generation of New Data
Decoders are the complementary component of encoder-decoder mechanisms, responsible for generating new data based on the embeddings provided by the encoder. In the context of machine translation, for example, the decoder takes the embeddings of the source language sentence and generates the corresponding translated sentence in the target language.
The decoder employs a language model to produce the output sequence. Language models can be autoregressive, where the generation of each token depends on the previously generated tokens, or non-autoregressive, where tokens are generated simultaneously, without considering the order of the output sequence. Autoregressive decoders are common in many NLP tasks due to their ability to generate coherent and contextually appropriate sequences.
Training the decoder involves minimizing the discrepancy between the generated output and the ground truth (desired output). This is typically achieved using techniques such as maximum likelihood estimation and teacher forcing during training.
The encoder and decoder work collaboratively, with the encoder providing a context vector or hidden state that serves as a summary of the input sequence. This context vector is then used by the decoder to initiate the generation process, helping it produce output sequences with meaningful information.
Tokens. Tokenization. Vectors, Matrices, and Functions
Section 3: The Significance of Tokens and Tokenization
3.1 Defining Tokens in NLP
In Natural Language Processing (NLP), a token is the smallest meaningful unit of text, which could be a word, a character, a part of a word, or even a sentence, depending on the level of granularity chosen for the specific NLP task. Tokenization is the process of breaking down raw text data into these individual tokens, making it possible for AI models to handle and process text efficiently.
The choice of tokens depends on the requirements of the task and the language being processed. For instance, in English, words are commonly used as tokens due to their semantic significance. In character-level tokenization, each character is considered a separate token, which is useful for languages without spaces between words, like Chinese or Japanese.
Tokenization is the first step in preparing text data for NLP tasks, and it is essential to maintain consistency and accuracy in representing the text.
3.2 Tokenization Techniques and Examples
Various tokenization techniques are employed in NLP, each with its advantages and drawbacks. Here are some common tokenization methods:
- Word Tokenization: This technique divides the text into words based on spaces or punctuation marks. For example, the sentence “Natural language processing is fascinating!” would be tokenized into [“Natural”, “language”, “processing”, “is”, “fascinating”, “!”].
- Character Tokenization: In character-level tokenization, each character becomes a separate token. For instance, the same sentence from above would be tokenized into individual characters: [“N”, “a”, “t”, “u”, “r”, “a”, “l”, ” “, “l”, “a”, “n”, “g”, “u”, “a”, “g”, “e”, ” “, “p”, “r”, “o”, “c”, “e”, “s”, “s”, “i”, “n”, “g”, ” “, “i”, “s”, ” “, “f”, “a”, “s”, “c”, “i”, “n”, “a”, “t”, “i”, “n”, “g”, “!”].
- Subword Tokenization: Subword tokenization splits words into smaller subword units, which can help handle rare or out-of-vocabulary (OOV) words. Popular subword tokenization methods include Byte-Pair Encoding (BPE) and SentencePiece. For example, “unbelievable” could be tokenized into [“un”, “believ”, “able”].
Tokenization plays a crucial role in preparing text data for various NLP tasks, enabling models to process and understand human language efficiently.
Section 4: The Mathematical Backbone: Vectors, Matrices, and Functions
4.1 Introduction to Vectors in AI
In the realm of Artificial Intelligence, vectors are essential mathematical entities used to represent and process data efficiently. A vector is a one-dimensional array that contains numerical values, with each element corresponding to a specific feature or dimension of the data. In Natural Language Processing (NLP), words or tokens can be represented as vectors, with each element of the vector encoding linguistic features or properties of the word.
For example, consider a simple word embedding representation for the word “apple”:

In this representation, the word “apple” is mapped to a vector in a four-dimensional space, where each element represents a specific linguistic attribute. These values are learned through training the model on a large corpus of text, enabling the model to capture semantic relationships between words.
Vectors allow AI models to perform mathematical operations such as addition, subtraction, and dot products, which are crucial in various AI tasks, including language understanding, machine translation, and sentiment analysis.
4.2 Working with Matrices in Encoder-Decoder Models
Matrices are two-dimensional arrays of numbers arranged in rows and columns. In encoder-decoder models, matrices are used to perform transformations and computations on vectors. For example, the word embeddings for an entire sentence can be stacked together in a matrix, where each row represents the word vector for a word in the sentence.
Suppose we have the following word embeddings for a sentence:
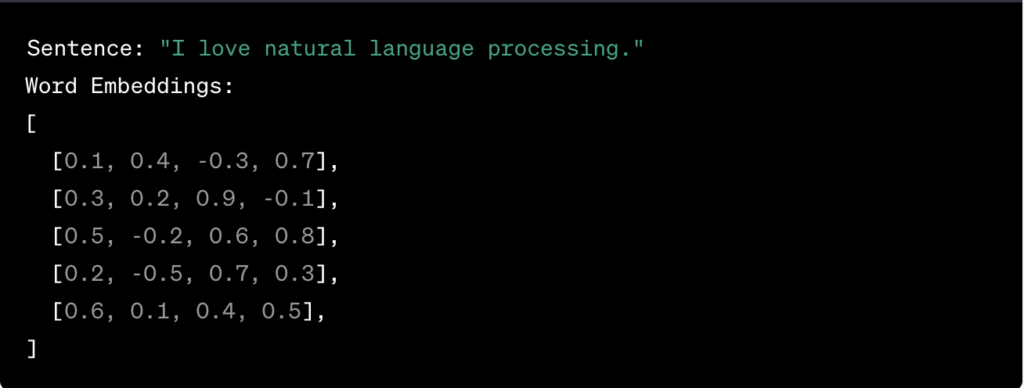
Matrices facilitate various operations in encoder-decoder models. For instance, in the attention mechanism of Transformer models, the matrix multiplication between the encoder’s word embeddings and the decoder’s word embeddings is used to calculate the importance of each word in the input sentence concerning the generation of each word in the output sequence.
4.3 Mathematical Functions in Encoder-Decoder Models
4.3.1 The Softmax Function
The softmax function is widely used in AI, particularly in classification and sequence generation tasks. In encoder-decoder models, the softmax function is used to convert raw scores or logits into probabilities. Given a vector of logits, the softmax function computes the probabilities of each element in the vector, ensuring that all probabilities sum up to 1.
For a given vector of logits z=[z1,z2…,zn], the softmax function is defined as:
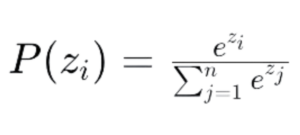
For example, consider the following vector of logits for a language model generating the next word in a sentence:

Applying the softmax function to these logits gives us the corresponding probabilities:

The softmax function is commonly used in the final layer of the decoder in sequence generation tasks, where it converts the raw scores into probabilities, allowing the model to select the most probable token for the next position.
4.3.2 Backpropagation and Training
Backpropagation is a critical training technique in deep learning, including encoder-decoder models. During the training process, the model’s parameters, including the weights in matrices and embeddings, are adjusted based on the gradients of the loss function with respect to these parameters.
In encoder-decoder models, the parameters are updated by propagating the error backward from the decoder to the encoder through the attention mechanism and hidden states. The gradients are calculated using techniques from differential calculus, such as the chain rule, where the error is successively attributed to each layer of the model.
The process of backpropagation enables the model to learn from the discrepancies between the generated output and the ground truth during training, refining the parameters to improve the model’s performance.
About The Author

Bogdan Iancu
Bogdan Iancu is a seasoned entrepreneur and strategic leader with over 25 years of experience in diverse industrial and commercial fields. His passion for AI, Machine Learning, and Generative AI is underpinned by a deep understanding of advanced calculus, enabling him to leverage these technologies to drive innovation and growth. As a Non-Executive Director, Bogdan brings a wealth of experience and a unique perspective to the boardroom, contributing to robust strategic decisions. With a proven track record of assisting clients worldwide, Bogdan is committed to harnessing the power of AI to transform businesses and create sustainable growth in the digital age.

Leave A Comment